“Just like architecture reviews in the R&D world or debriefs and after-action reports in the military world, we too need a process for improvement in incident management, response, containment and remediation.”
– Sam Curry, CSO

GOALS OF A POST-INCIDENT REVIEW

Address the problem from the very beginning, not just the end.

Iteratively assess the complete picture of damage to prevent future incidents.
Mature your security program by investigating attacks from start to finish.
Low and Slow Attacks
With low and slow attacks, the attacker’s progress across the kill chain may be scattered across a long timeline involving different network segments or third-party channels to the network. Attackers may use different tools and techniques in each part of the attack, access the data they want, and then remove any trace of activity. These attacks pass under the radar of many security products where data retention time is short and event correlation over time is weak.
SEE THE FULL SCOPE OF THE ATTACK
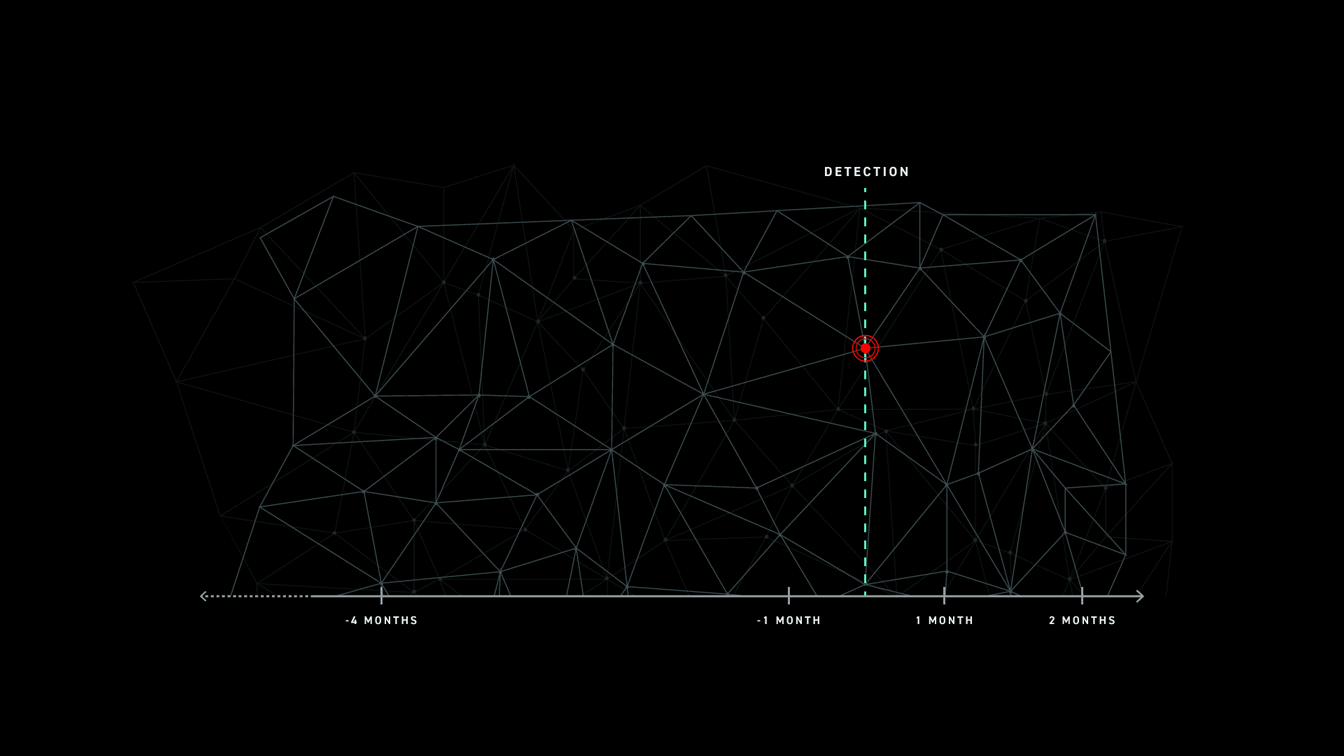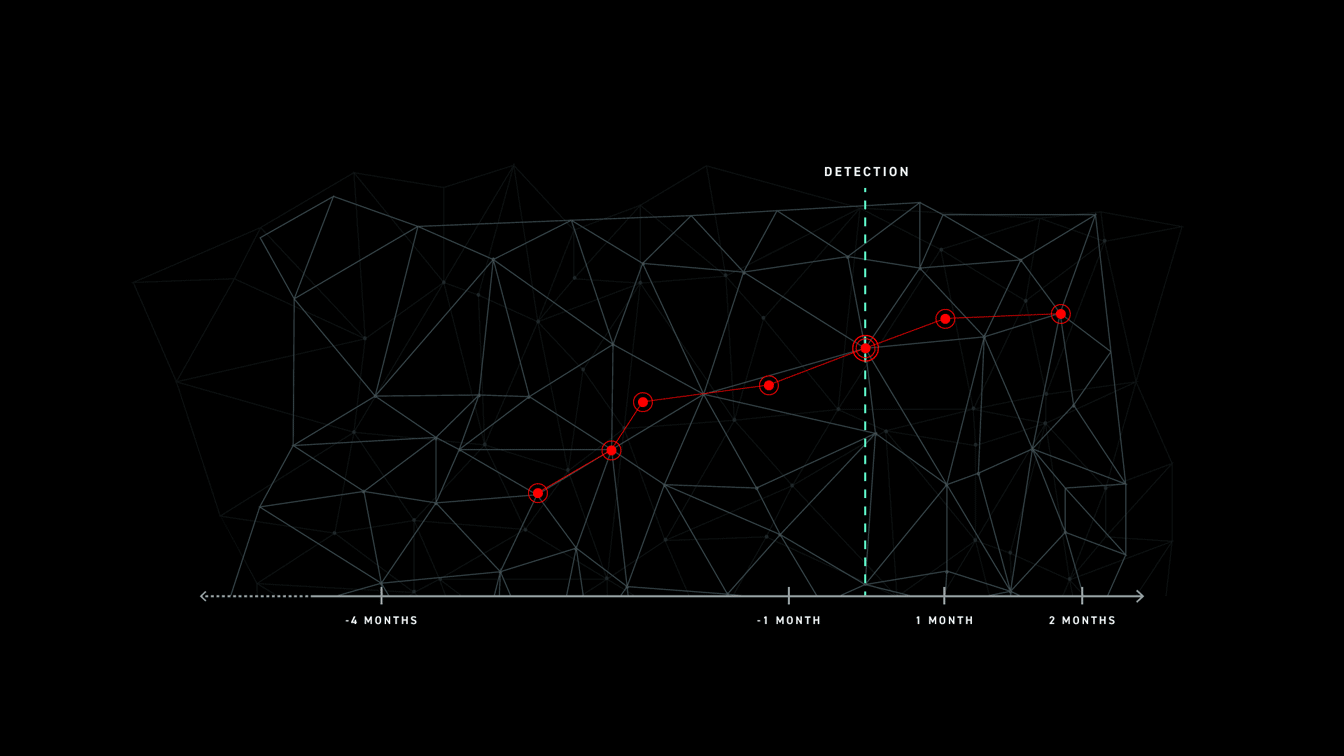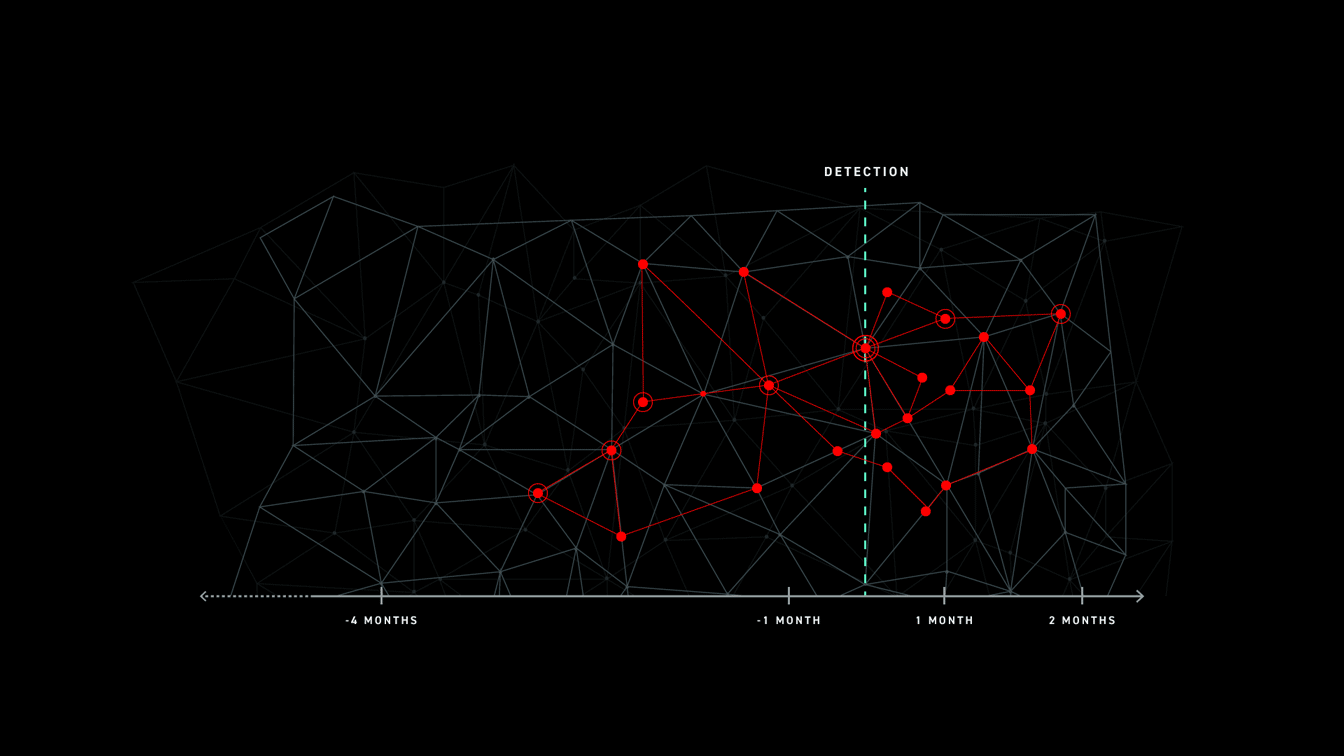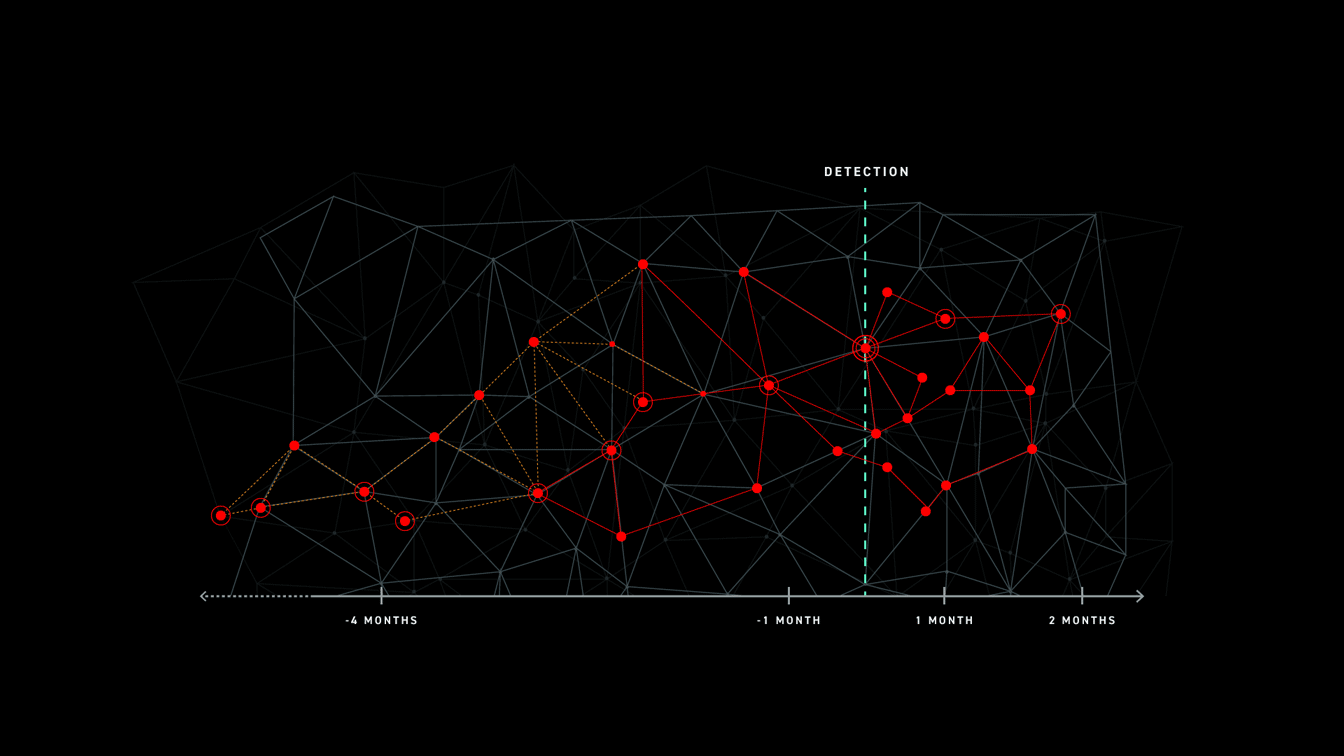
In these instances, defenders are unable to get the full picture of an attack and are only able to remediate the final, most recent stages. This leaves exposed areas for attackers to target.
The Nation State
For example, nation-state threat actors may begin their attack with a commodity cyber attack framework. They scan the perimeter for vulnerabilities, gain access to a specific endpoint or server, steal local admin credentials, and wait. They wait to use the credentials weeks later to regain access to the network. Once in, they use different tools and techniques to accomplish their main attack objectives. In this case, the attack is only detected in its last stages. If the retention time of the SIEM or EDR is smaller than the length of the attack, the defender is going to miss the initial compromise in their review. They will only respond to the final stages and be totally oblivious to the bigger picture. This leaves the network exposed to those same exploits and entry points the attacker used at stage 1.



.png)
OPERATION SOFT CELL
In 2018, the Cybereason Nocturnus team identified an advanced, persistent attack targeting global telecommunications providers carried out by a threat actor using tools and techniques commonly associated with the Chinese-affiliated threat actor APT10. This multi-wave attack focused on obtaining data of specific, high-value targets and resulted in a complete takeover of the network.
Read About the Attack →
What Happened Before the Attack?
Look back in time to before the incident started. Are there any indications the attacker is already in your environment?
EXACTLY WHAT HAPPENED, AND AT WHAT TIME?
Walk through the incident step by step. Identify what happened before detection, during investigation, during response, and after remediation.

HOW WELL DID THE TEAM HANDLE THE INCIDENT?
Talk about if the SOC was well-prepared for the incident. Were they able to resolve it quickly? Was someone on call to handle it?

WHAT INFORMATION WAS NEEDED SOONER?
Consider the information your team was able to gather about the incident. Were they well-prepared to react? How much time passed before remediation?

WERE ANY STEPS TAKEN THAT INHIBITED RECOVERY?
Consider whether the processes followed was as efficient and effective as it could be. What can be optimized? What can be removed?

WHAT COULD THE TEAM DO DIFFERENTLY THE NEXT TIME AN INCIDENT OCCURS?
Consider if each member of the team contributed as effectively as possible. Does the team understand what they need to do? Do they need training?
WHAT CORRECTIVE ACTIONS CAN PREVENT SIMILAR INCIDENTS?
Retrospectively analyze every piece of the attack. How far back can you find the attacker in your system?
WHAT ADDITIONAL TOOLS DOES THE TEAM NEED TO PREVENT THIS?
Did your team have the visibility it needed to resolve the incident completely? Think of good wish list items that you want your team to have to succeed.
How did management handle this incident?
Consider if management was well-prepared for an incident. Were lines of communication open? Did management understand the gravity of the situation?
EXISTING SECURITY TOOLS ARE NOT ENOUGH

Network forensics is useful, but is limited to 2-4 weeks worth of raw data, with a few additional weeks for metadata. Further, capturing and storing packet capture is expensive.

The main driver for longer data retention is compliance. Vendors offer a way to efficiently compress and archive data, but no easy way to access and correlate it.

Cloud-delivered platforms are a step in the right direction, but the cost of data shifts to the vendors, who have little incentive to store and pay for all that data.