
Genesis Market - Malicious Browser Extension
In this Threat Alert, Cybereason identifies a malware infection exhibiting similarities to a previous Genesis Market campaign.

In a recent post, the Cybereason Global SOC team reported an aggressive ransomware campaign attributed to the Black Basta group:
In this threat alert, the Cybereason team describes one attack scenario that started from a Qakbot infection, resulting in multiple key machines loading Cobalt Strike, which finally led to the global deployment of Black Basta ransomware.
This attack has become the bread and butter of the hacking industry. Just this week, we’ve seen Dole shutting down production in North America due to a similar attack. Now, reports are coming in of the U.S. Marshals Service being hit by ransomware resulting in the theft of employees' personal data.
We see the same pattern — breach → expansion → damage — repeatedly applied by many attack groups, each using slightly different tools. Whether it’s Black Basta, Royal Ransomware, or Hive Ransomware, there’s almost a formula to it: Take one or two existing attack tools, make the occasional minor modification, and employ them with significant success. Names and members of groups change, but their tools of choice remain the same.
Cobalt Strike was initially released in 2012, and other common attacker payloads – such as Qakbot – have been around since 2008. They are high-profile tools drawing significant defender attention. These enduring multipurpose attack payloads have become the cornerstone of most major attacks today.
Cobalt Strike, Meterpreter, and others, such as the recently popular Brute Ratel, provide attackers with a swiss army knife spanning the entire MITRE ATT&CK™ framework. This allows attackers to use them in ever-changing scenarios. Moreover, these payloads are continuously developed, with new releases every few months, leaving defenders and vendors always playing catch-up. If these payloads are so dangerous, why are vendors still struggling to detect them? Why are they still so hard to stop?
First, their rapid development makes most detections obsolete when a new version is released. Second, the malicious developers work continuously to keep up with all the latest detection techniques and ensure they avoid detection before release. Third, it has become easier to generate an endless stream of unique payloads with variations in encryption, compression, and compilation methods, all with the touch of a button.
“How hard could that be?” (famous last words, ca. 2019)
In 2019, we identified this challenge in Cobalt Strike, which was gaining popularity and was encountered in multiple high-profile attacks. We ran through several iterations of ideation, research, prototyping, and red team exercises. The real breakthrough came when we realized we must go back to basics: We needed to look for the bottleneck where attackers are most exposed. We noticed that in the case of those attack payloads and most other high-profile malware, their strength is also their weakness: They behave like any other large software project.
Applying modern software development processes is a good way to build successful attack payloads but also exposes them. Any complex software project relies on many widely reused and rarely modified parts. Whether it’s a compression algorithm or a tailored memory loader, these pieces become the “core genes” of the software. Even evasive malware has to be loaded to memory for execution eventually. If we could effectively detect these code parts in memory, we would have a resilient method of blocking these threats for the long term.
All we need then is a way to detect code in memory. Specifically, we need to detect compiled code that accumulates many small changes every time it’s compiled and/or loaded and appears in memory only briefly. Naturally, we must be confident of blocking it from running and doing all that in a few milliseconds. How hard could that be?
This problem required a new approach, so we introduced the concept of Fuzzy Similarity. To explain fuzzy similarity, let’s consider a practical example. In our example, we have two samples of Qakbot, and we’d like to use the first sample to make a fingerprint, which could then detect the second sample (and, hopefully, other future samples out there). We have gone ahead and found an important piece of the malware code. Here’s how it appears in the two samples:

We could try searching for the bytes on the left as-is: `2B D8 .. .. 33 C0`. This would fail as some bytes in the other sample are different. Even a trivial re-compilation results in different internal offsets of imported functions.
One way to tackle this problem is to let an expert decide which bytes go into our signature, for example, `68 ?? ?? ?? 00 E8 ?? ?? ?? FF` and so on. YARA signatures are a typical way of applying this approach. While useful for some scenarios, this method is unsuitable for the task. Crafting these signatures requires a lot of expert work and many samples, and their detection power is very limited - even a minor change of code or compilation flags can overcome such signatures.
Things get even worse when attempting to detect this code in memory. Code representation in memory is very noisy, with random content being introduced between opcodes, relocation modifying address offsets, and content order changing due to space considerations. The hand-crafted expert signature approach simply doesn’t scale.
In contrast, the fuzzy similarity approach doesn’t attempt to create clear-cut signatures. It instead defines a method for taking any two pieces of data (e.g., compiled binary code) and measuring the level of similarity between them (usually expressed as a percentage). A good fuzzy similarity method would give our two Qakbot samples a high similarity score. It would give a very low score when comparing one of these samples to any other random piece of code taken from some unrelated piece of software.
One example of this approach is “ssdeep,” introduced in a 2006 paper. Briefly, this tool digests whole files into hash strings, with each character representing a direct hash of a contiguous chunk of the full content. Levenshtein distance is then applied to these hashes as a measure of similarity. However, like most attempts in this field, it falls short on a critical point of graduality. Its scores are “hit or miss”: Two samples with long enough identical sub-sequences are identified as a match, but they’re considered completely unrelated in any other case.
In this stark prism, Word 2007 is as similar to Excel 2011 as it is to Cobalt Strike or Meterpreter. Without graduality, the fuzzy fingerprints aren’t sensitive enough to identify and block malware in memory.
Cybereason’s Variant Payload Prevention (VPP) employs a new proprietary algorithm for fuzzy similarity. We call this algorithm Binary Similarity Analysis (BSA). Drawing inspiration from Locality Sensitive Hashing techniques, this algorithm can measure the similarity between two samples with effective sensitivity across a gradual range of similarities. With fingerprints that a fully automated process can generate, it can identify derivative or related malware even after repeated accumulated modifications. Its sensitivity also means that it is very hard to introduce changes that circumvent the detection.
To illustrate this point, we can look at the relative similarities between our two Qakbot samples, the same code when loaded into memory, and a few unrelated pieces of software:
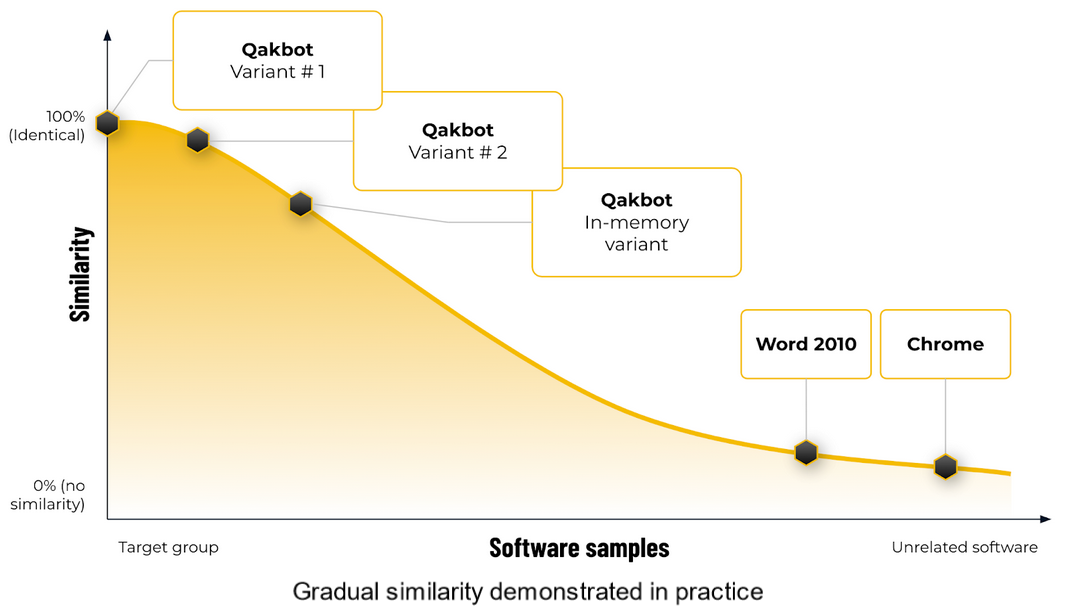
On the left, we see how variations in Qakbot code (recompilation, memory loading) result in an almost perfect similarity, while unrelated pieces of code are receiving dramatically lower scores.
Furthermore, the wide gap in the middle reflects our safety buffer against false positives: it is extremely unlikely that any unrelated piece of software would contain code that would come close to crossing this gap.
With this algorithm, an expert analyst already has the power to generate sustainable fingerprints through manual research work. While this is powerful, the BSA technology lets us take another step forward: We can use the same algorithm to automate fingerprint generation.
The automatic generation of fingerprints takes inspiration from the “shotgun” method for genome sequencing. This process is composed of three phases:
|
Step 1: |
 |
|
Step 2: |
 Identifying significant ranges of Qakbot code Identifying significant ranges of Qakbot code |
|
Step 3: |
 |
The outcome of this process is a clean set of hyper-sensitive fingerprints ready to be used for detecting the specific malware family we’re after. It’s worth noting that this process sometimes has an additional surprising result. In the third phase, we often see cases where one malware sample is discovered to be unusually similar to those of another malware family. This provides insight into relations between malware families and developer groups and discovers previously undetected samples that have flown under the radar for years.
With the fingerprints we generated, it’s now possible to scan any chunk of binary data using a sliding window to detect matching regions in a predictable time and quickly. These chunks may originate from many sources, but files and executable memory regions are the most important.
Attackers have two ways to run their code: through the door or the window. Bring your executable as a file or unscrupulously get your code into memory. Since scanning executable files before running them is an established industry standard, many attackers opt for the latter approach. That is why we consider it critical to have an effective memory-scanning capability.
While many vendors monitor these bottlenecks using user mode hooks, which are very easy to evade and remove, Cybereason VPP uses kernel hooks which are practically impossible to evade. Combining these capabilities with the BSA technology, we can offer our customers unprecedented protection against the most advanced and recent malware.
Modern attack payloads allow anyone with a little know-how to execute cyber campaigns with capabilities that previously were available only to nation-state actors. It is imperative that, as an industry, we figure out a way to discover the weak points of this phenomenon and counter its devastating effects. We consider the addition of VPP capabilities to our endpoint protection platform as a way of giving defenders the technological edge they sorely need to mitigate these threats.
 Yonatan Perry
Yonatan Perry
Yonatan Perry is Director of Data Science at Cybereason. He has
 Uri Sternfeld
Uri Sternfeld
Uri Sternfeld is Chief Scientist at Cybereason. Uri is a

Cybereason is dedicated to partnering with Defenders to end attacks at the endpoint, in the cloud and across the entire enterprise ecosystem. Only the AI-driven Cybereason XDR Platform provides predictive prevention, detection and response that is undefeated against modern ransomware and advanced attack techniques. The Cybereason MalOp™ instantly delivers context-rich attack intelligence across every affected device, user and system with unparalleled speed and accuracy. Cybereason turns threat data into actionable decisions at the speed of business.
All Posts by Cybereason Team
In this Threat Alert, Cybereason identifies a malware infection exhibiting similarities to a previous Genesis Market campaign.

This report provides an overview of key features of the Snake #malware and similarities discovered in the staging mechanisms with two other information-stealing malware variants, FormBook and Agent Tesla...